
Data breaches and cyberattacks pose major threats to organizations dealing in sensitive information today. To address these challenges, data masking has emerged as a critical tool for protecting confidential data while maintaining its usability. Data masking is changing sensitive data in a realistic fictitious way that maintains security with assurance of compliance and without interference to workflow processes. This article will elaborate on the inner mechanics of algorithms behind data masking, their types, and how they apply in practice.
What is Data Masking?
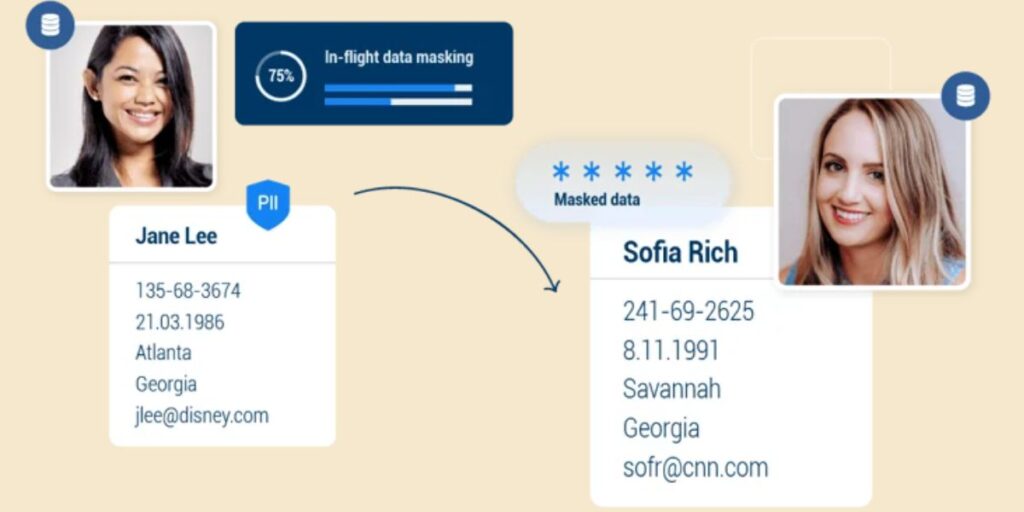
Data masking is any process that transforms sensitive data to render it usable but useless to unauthorized users. For example, actual customer names or credit card numbers may be replaced with fictitious values, but the overall data format and functionality are preserved, thus the data remains useful for non-production uses such as testing or analytics.
Data masking effectiveness is a balance between security and usability. Masked data needs to be close enough in structure to the original not to disrupt applications while remaining secure enough to prevent reverse engineering or unauthorized identification.
Types of Data Masking
Static Data Masking
Static Data Masking involves copying key datasets and masking sensitive information, without affecting original data. The masked dataset is then utilized in the non-production environment for either software testing or training sessions. Before sharing any type of information about customers with a third-party vendor, for example, organizations can replace real credit card numbers with masked values.
Dynamic Data Masking
DDM masks the sensitive data right at the point of access, in real time, without affecting the original database. This is usually useful in live systems, where different users require differential access to the same dataset. For example, at a bank, a bank teller will see only masked versions of a customer’s account balance, while that would be open for the manager.
Deterministic Masking
Deterministic masking will always produce the same output for a given input. This ensures consistency across multiple systems, and therefore is ideal for scenarios where relational integrity is crucial. In such a case, one could mask customer IDs consistently across several databases and correctly cross-reference them without peering at real identifiers.
On-the-Fly Masking
On-the-fly masking of data is done when data is transferred from one environment into another, such as in system integrations or cloud migrations. Thereby, sensitive information gets masked before it reaches the less secure environments, which enhances data protection in transport.
How Data Masking Algorithms Work
Character Shuffling
Character shuffling jumbles the characters of the data element in order to obscure its value while keeping its structure intact. For instance, a phone number like “1234567890” could become “0987654321.” This approach is quite simplistic and thus faster, but it may be subject to reverse engineering if certain patterns start to emerge.
Substitution
Substitution replaces sensitive data with values defined beforehand, or even random values. For example, substitution of “John Doe” with “Jane Smith” preserves the realness of the data in testing or training. The effectiveness of substitution often depends on unicity to avoid conflicts in the datasets.
Masking Keys Encryption
This technique couples encryption with masking, where the data is encrypted by a key that can be reversible. Only authorized systems will be able to decrypt that information; it thus adds an additional layer of security. These techniques are quite useful in those environments where data must not be available for some time, but it should remain accessible to all trusted parties.
Tokenization
The sensitive data, as part of tokenization, gets replaced by a specific, unique token, which is then further stored in a secure database. A credit card number like “1234-5678-9012-3456” would be replaced by something like “abcd-efgh-ijkl-mnop.” This methodology is very widely applied in compliance-driven verticals since it offers good protection without losing usability.
Randomization
Randomization typically introduces random values to represent the data, whereby any association to the source is lost. It’s highly secured but may affect usability for applications that require predictability.
Factors to Consider When Choosing a Data Masking Algorithm
Regulatory Compliance
Financial and health industries are regulated to ensure data protection with regulations like PCI DSS and HIPAA, respectively. It is worth mentioning that selection needs to consider only those algorithms that keep regulatory compliances intact. This is due to the fact that failure to comply with them may bring additional legal penalties and loss of consumer trust.
Data Sensitivity
Highly sensitive data, like PII, requires high methods of masking, such as encryption or tokenization. Less important information can be provided with simpler methods, such as substitution.
Relational Integrity
Many applications rely on maintaining relationships across datasets. Consider deterministic masking for example: a masked customer ID needs to remain identical in both the source and target databases to ensure data consistency.
Performance Requirements
Real-time systems benefit from efficient algorithms like substitution or character shuffling, each offering very minimal latency. In contrast, static environments can accommodate methods that are computationally intensive, like encryption.
Practical Applications of Data Masking
Software Development and Testing
In software development, there is often a need to test it with data that is realistic. Data masking enables developers to work with functional data sets without letting sensitive user information be revealed. For example, a masked database can simulate user transactions in a financial application.
Data Shared with Third Parties
Sharing information with third-party vendors or partners means that the information will be accessed by people for whom the owners did not originally intend. Masked datasets ensure sensitive information integrity, even in cases of a compromise.
Cloud Migrations
Data masking gives organizations better security for their data both in transit and at rest as they move into the cloud. For instance, personal data that may be stored on-premise in a database can be masked before its upload to analytics platforms that are situated on the cloud using data masking.
Analytics and Reporting
Masked data retains its value in generating insights but protects privacy. Demographic data could be masked for marketing purposes, without disclosing identities of individuals.
Conclusion
Masking is an indispensable component of sensitive information protection, enabling a group to work with functional data while minimizing exposure risk. Understanding how various algorithms work and where to use them will lead quite a distance to strengthening data security strategies. Besides, it involves developing techniques for masking that meet regulatory, performance, and relational requirements to balance the protection of information assets with operational efficiency and compliance of the business. In this era data security, effective investment in data masking solutions is not only prudent but also key.





